

From SIMD to MIMD: The Evolution of Modern Computing in GPUs and AI
Blending Architectures: The Power of Hybrid Paradigms

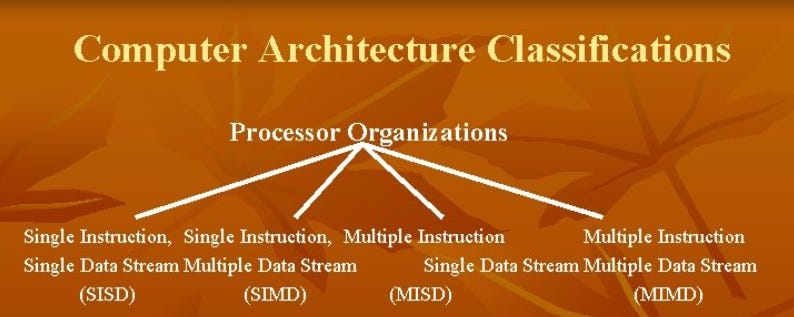
Processing data efficiently is a cornerstone of modern computer architecture. Flynn's Taxonomy, introduced in 1966 by Michael J. Flynn, provides a framework to classify computing architectures based on the number of instruction and data streams they handle. Here we will discuss the four paradigms of Flynn's Taxonomy.
Flynn's Taxonomy: The Basis of Processing Paradigms
Flynn’s model is based on two key elements:
Instruction Streams: Sequences of instructions executed by a processor.
Data Streams: Sequences of data on which the instructions operate.
These form the basis of the four categories:
SISD: Single instruction operating on a single data stream.
SIMD: Single instruction operating on multiple data streams.
MISD: Multiple instructions operating on a single data stream.
MIMD: Multiple instructions operating on multiple data streams.
1. Single Instruction Single Data (SISD)
Instructions are executed sequentially but may be overlapped in their execution stages. In other words pipelining technique can be used in CPU. An SISD computer may have more than one functional unit in them, but all are under supervision of one control unit. SISD architecture computers can process only scalar type instructions. They are commonly used where
We do not need parralel processing
We require sequential execution of tasks
It has following characteristics
Single Control Unit (CU): Executes one instruction at a time.
Single Data Stream: Operates on one piece of data at a time.
Sequential Execution: Processes tasks sequentially, with no parallelism.
Examples
Traditional uniprocessor systems such as early personal computers (e.g., Intel 8086).
SISD computer using multiple functional units such as IBM 360/91, CDC Star-100, TI-ASC
Simple embedded systems where efficiency and simplicity are prioritized.
")
Limitations
Poor scalability: As computational demands grow, SISD systems struggle to keep pace due to their lack of parallelism.
2. Single Instruction Multiple Data (SIMD)
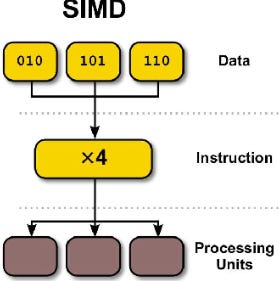
A single instruction controls multiple processing elements to perform operations on different pieces of data concurrently. In SIMD architecture, a processor executes one instruction at a time, but this single instruction is applied to a set of data rather than a single data point. For example, if a task involves adding two large arrays of numbers, a SIMD-equipped processor could add corresponding elements from each array in a single operation, rather than iterating through the arrays and adding pairs of numbers one at a time.
It is used in
Image and video processing: Applying the same operation to multiple pixels or frames.
Scientific simulations: Calculations on large datasets, such as matrix multiplication.
Machine learning: Neural network operations benefit significantly from SIMD parallelism.
Characteristics
Single Control Unit: Executes a single instruction across multiple data elements simultaneously.
Data-Level Parallelism (DLP): Exploits parallelism in datasets, making it highly efficient for tasks with repetitive operations.
Hardware Implementation: Typically includes vector processors or specialized instruction sets in modern CPUs and GPUs.
Examples
Vector Processors: Early examples include the Cray-1 supercomputer.
Modern CPUs and GPUs: Technologies like Intel’s AVX (Advanced Vector Extensions) and NVIDIA’s CUDA leverage SIMD principles.

Limitations
Requires uniformity: Tasks must perform the same operation on all data elements, which limits flexibility.
Tasks that have a high degree of data dependency may not benefit as much from SIMD parallelism.
3. Multiple Instruction Single Data (MISD)
It indicates that multiple instructions are applied to the same set of data. MISD architecture is also known as systolic arrays.
In MISD computer architecture:
there are n processor elements.
Each processor elements receives distinct instructions to execute on the same data stream and its derivatives.
Here the output of one processor element becomes the input of the next processor element in the series.
Examples
There is no practical example of MISD yet.

Limitations
Limited scalability and efficiency for general-purpose computing.
Challenging to find real-world problems that fit this model.
4. Multiple Instruction Multiple Data (MIMD)
MIMD architecture involves multiple processors that execute different instructions on different data sets thus exhibiting parallel computing. Thus we can also say that MIMD belongs to class of parallel computing architecture.
Machines using MIMD have a number of processors that function asynchronously and independently. At any time, different processors may be executing different instructions on different pieces of data.
MIMD machines can be of either shared memory or distributed memory categories. These classifications are based on how MIMD processors access memory. Shared memory machines may be of the bus-based, extended, or hierarchical type. Distributed memory machines may have hypercube or mesh interconnection schemes.
It is used in multithreaded and multi tasking applications and high performance computing such as big data analytics, cryptography and design for testibility. Training complex AI models often involves MIMD architecture.
Characteristics
Multiple Control Units: Execute different instructions independently.
Multiple Data Streams: Each processor operates on its own dataset.
Task-Level Parallelism: Suitable for complex and heterogeneous workloads.
Examples
Multicore Processors: Modern CPUs with multiple cores (e.g., AMD Ryzen, Intel Core).
Distributed Systems: Clusters and cloud computing infrastructures.
GPUs: Although primarily SIMD-oriented, some GPUs employ MIMD principles for specific tasks.
Supercomputers: High-performance supercomputers, such as the IBM Summit.
Limitations
Higher complexity: Requires sophisticated synchronization mechanisms.
Power consumption: Running multiple processors simultaneously demands significant energy.
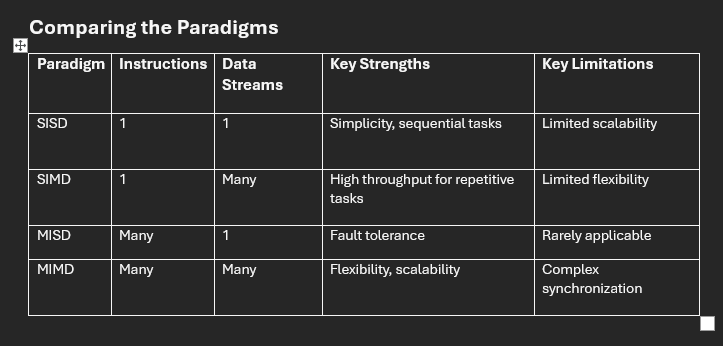
Comparing the Paradigms
Relevance in Modern Computing: GPUs and AI Accelerators
Modern computing systems often integrate multiple paradigms from Flynn’s Taxonomy to optimize performance for diverse workloads.
GPUs: Primarily SIMD with MIMD Principles
Graphics Processing Units (GPUs) are designed for massive parallelism and are predominantly based on the SIMD paradigm. However, they incorporate certain aspects of MIMD to handle more complex workloads.
SIMD Foundation in GPUs:
GPUs excel at tasks requiring the same operation to be performed on large datasets, such as rendering images, video processing, and scientific simulations.
Each core in a GPU executes the same instruction across multiple data points, such as performing matrix multiplications in deep learning or applying filters to pixels in image processing.
SIMD enables GPUs to process thousands of threads simultaneously, ensuring high throughput for repetitive, data-parallel tasks.
MIMD-Like Features in GPUs:
Modern GPUs, such as NVIDIA’s Ampere or AMD’s RDNA architectures, support independent thread scheduling, allowing different processing cores to execute distinct tasks concurrently.
This flexibility is critical for heterogeneous workloads in gaming, real-time ray tracing, and general-purpose computing on GPUs (GPGPU).
APIs like CUDA and OpenCL enable programmers to write code that leverages this combination, allowing some threads to handle complex calculations while others execute simpler ones.
Applications:
Gaming and Graphics: Real-time rendering and physics simulations depend on the SIMD strengths of GPUs.
AI and Machine Learning: Training and inference for deep learning models involve parallel matrix operations, leveraging both SIMD for bulk computation and MIMD for managing control-flow divergence in neural network layers.
AI Accelerators: Systolic Arrays with MIMD Flexibility
AI accelerators, such as Google’s Tensor Processing Units (TPUs) and custom chips like Apple’s Neural Engine, blend paradigms to optimize for machine learning tasks.
Systolic Arrays (SIMD-Like Paradigm):
AI accelerators often include systolic array architectures, where a grid of processing elements performs the same operation on different chunks of data in a pipeline-like manner.
These arrays are highly efficient for matrix multiplications,which is very important in deep learning.
By streaming data through the array, accelerators achieve low latency and high energy efficiency, ideal for inference tasks in AI.
MIMD Principles for Flexibility:
To support diverse AI workloads, accelerators often include additional cores capable of independent execution.
For example, control-flow-heavy operations like decision trees or recurrent neural networks require MIMD-style task execution.
Specialized frameworks (e.g., TensorFlow, PyTorch) dynamically allocate tasks to either SIMD-like systolic arrays or general-purpose cores, ensuring optimal performance.
Applications:
Natural Language Processing (NLP): Models like GPT and BERT rely on accelerators to manage billions of parameters.
Autonomous Vehicles: Real-time decision-making combines parallel processing for sensor data with sequential logic for navigation.
Edge AI: Devices like smartphones and IoT sensors benefit from accelerators that blend SIMD efficiency with MIMD flexibility for local inferencing.
Conclusion
Understanding processing paradigms like SISD, SIMD, MISD, and MIMD is crucial for grasping the evolution of computer architecture. Each paradigm serves unique purposes, from the simplicity of SISD to the flexibility of MIMD. By leveraging the strengths of these paradigms, modern systems achieve unprecedented levels of performance and efficiency, enabling advancements in fields like AI, HPC, and scientific research.
The blending of SIMD and MIMD in GPUs and AI accelerators illustrates a shift in computing towards hybrid architectures. These systems aim to strike a balance between throughput and flexibility, enabling advancements in fields such as artificial intelligence, gaming, and real-time systems. By leveraging Flynn’s Taxonomy as a guiding framework, modern architectures achieve unparalleled performance and adaptability, pushing the boundaries of what is computationally possible.
Connect with Me:
GitHub: ranaumarnadeem/HDL
Medium: @ranaumarnadeem
Substack: We Talk Chips
LinkedIn: Rana Umar Nadeem
Tags: #DigitalLogic #CombinationalLogic #Decoders #Verilog #HDL #DigitalDesign #FPGA #ComputerEngineering #TechLearning #Electronics #ASIC #RTL #Intel #AMD #Nvidia #pipelining #interlocking #hazards #SIMD #SISD #MISD #MIMD #Hybrid_architecture #GPU #systolic_arrays