

Out-of-Order Execution: The Key to Faster and Smarter CPUs
Solving Data Hazards: The Role of Out-of-Order Execution in Modern CPUs

In traditional in-order execution processors face several challenges that limit their performance, including pipeline stalls, data hazards, inefficient resource utilization, and difficulties with handling memory latency and branch instructions.
Consider a scenario where an instruction needs to fetch data from memory, a process that takes several cycles. Meanwhile, the CPU remains idle, even though other instructions that don't depend on the fetched data could be executed in the meantime. This idle time leads to wasted CPU cycles and reduced overall performance.
If there is a true dependency ,other instructions have to wait as the pipeline is stalled. At that time there must be some instructions that are not dependent on the instrcution that is being processed . To make sure that such instructions do not have to wait we use OOO execution.
Out of Order Execution(OOO)
Out-of-Order Execution (OOO) is a powerful technique used in modern processors to boost performance by dynamically reordering instructions for execution. This approach helps overcome the limitations of traditional in-order execution, where instructions are executed strictly in the order they appear in the program. By executing instructions based on resource availability and readiness of operands, OOO can greatly improve the efficiency of a CPU.
OOO execution allows the CPU to identify and execute instructions that are ready to be processed, regardless of their original order in the program. This way, the processor can keep busy and reduce idle time.


IMUL instruction stalls the pipeline as the next instruction ADD is dependent on results of r3. In OOO the compiler will move the other 3 instructions above as they are independent and process them first.
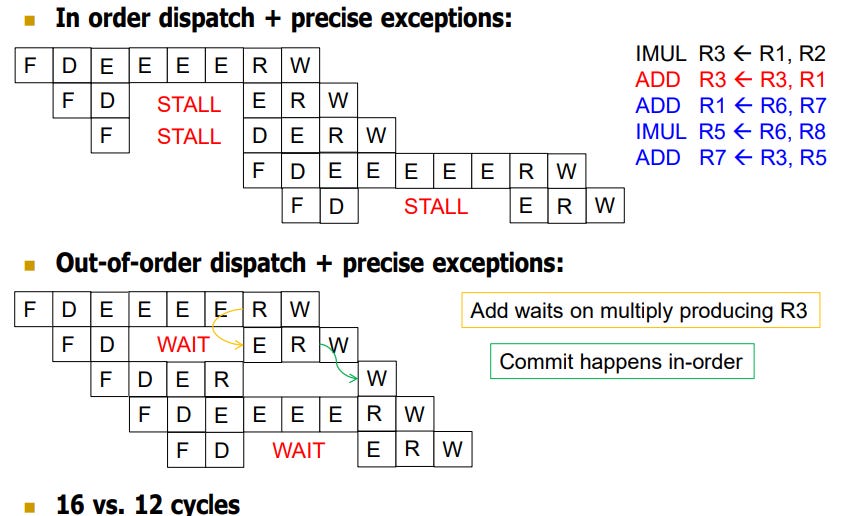

How Out-of-Order Execution Works
OOO execution uses a reorder buffer to reorder instructions before commiting them to architectural state. In most modern processers a Reorder Buffer is used to support retirement of instrcutions. A Single Instructions file is used to store all registers which contains both speculative(renamed) registers and architectural registers. Two Register Maps the frontend/future register map does renaming while Architectural Register Map maintains precise state.
Instruction Fetch: The processor fetches multiple instructions from the program memory, but instead of executing them immediately, it decodes them and checks for dependencies.
Instruction Queue: Decoded instructions are placed in an instruction queue. The processor then checks which instructions are ready to be executed. Instructions that are not dependent on previous ones can be executed immediately, even if they appear later in the program.
Execution: Instructions are executed as soon as their operands are available. This allows the processor to use its resources more efficiently, executing multiple instructions in parallel.
Reorder Buffer: Since instructions are executed out of order, the results are stored in a special buffer called the Reorder Buffer (ROB). The ROB ensures that the results are committed in the correct order, maintaining the illusion of in-order execution to the software.
Commit Stage: Once all instructions have been executed and their results are in the ROB, the processor commits the results to the architectural state (registers, memory) in the original program order. This step ensures that the program behaves as expected, despite the out-of-order execution.
To summarize, register renaming eleminate false dependencies and enables linking of producer to consumer. Buffering in reservation stations enables the pipeline to move for independent instructions.
OOO execution of Load and Store instructions
Register dependencies are known statically and can be renamed easily
On the other hand memory is dynamic , we need to execute it a little to get address. We cannot determine address at begining of pipeline
Register state is small and memory is huge.
Register state is not visible to other threads/processer while the memory is shared between other threads/processers (in a shared memory multiprocesser)
Memory Dependence Handling
We need to obey memory dependencies in an out of order machine. We want correct load to get correct value from correct store.
Since, memory address is not known until a load/store instrcution is executed.
So it is very hard to rename memory. This cannot be done during decode stage
Its possible that load is ready after 2 cycles but store needs a 1000 cycles.
When a load/store instruction has its address ready there maybe older/younger store/loads with unknown address in machine.
A problem is a younger load can have its address ready before the older stored address is known.
This is called Memory Disambigation problem or Unknown Address problem.
Approach:
Conservative: Stall load until all previous stores have computed their addresses (or even retired)
Aggressive : Assume load is independent of unknown address stores and schedule the load right away.
Intelligent: Predict if load is dependent or any unknown addess is stored
Memory Disambigation:
Option#01: Assume load is dependent on all previous stores. If we do this there is no need for recovery but it is too conservative it would delay independent loads unnecssarily .
Option#02: Assume load is independent of all previous stores.This is simple and can be common case as there would be no delays for independent loads. But it requires recovery and re-execution of load on mispreduction.
Option#03: Predict dependence of load on an outstanding store. This is more accurate but still requires recovery and re-execution on misprediction.
Real-World Examples of OOO Processors
Out-of-Order Execution is a common feature in modern high-performance processors, including:
Intel Core Series: Intel's Core series processors, such as i5 and i7, use OOO execution to improve performance in a wide range of applications, from gaming to content creation.
AMD Ryzen: AMD's Ryzen processors also leverage OOO execution to compete with Intel in terms of performance, especially in multi-threaded workloads.
Connect with Me:
LinkedIn: Rana Umar Nadeem
Medium: @ranaumarnadeem
GitHub: ranaumarnadeem/HDL
Substack: We Talk Chips
Tags: #DigitalLogic #CombinationalLogic #Decoders #Verilog #HDL #DigitalDesign #FPGA #ComputerEngineering #TechLearning #Electronics #ASIC #RTL #Intel #AMD #Nvidia #pipelining #interlocking #hazards #data_dependency #branchprediction #fine_grained_multi_threading #computer_organization #OOO #stalls